Signal-32: Assess Your Next Investment in 32 Questions
Overview
Prove your gut feeling.
Signal-32 helps angel investors quickly assess the potential of AI startups through a 32-question quantitative framework, benchmarked against early-stage data from 24 successful AI companies. The tool adheres to the philosophy of "investing in people" — the questions draw from the experience of Sequoia Capital, Benchmark, and other firms, focusing on the founding team itself. For reference only, not investment advice.
Context
Do you need an internal tool to quickly validate your intuition?
I developed Signal-32, which compiles mainstream VC evaluation criteria for AI startups — team background, research depth, product execution, data and distribution, and AI competitive advantages — enabling anyone to swiftly assess whether the person in front of you is worth investing in.
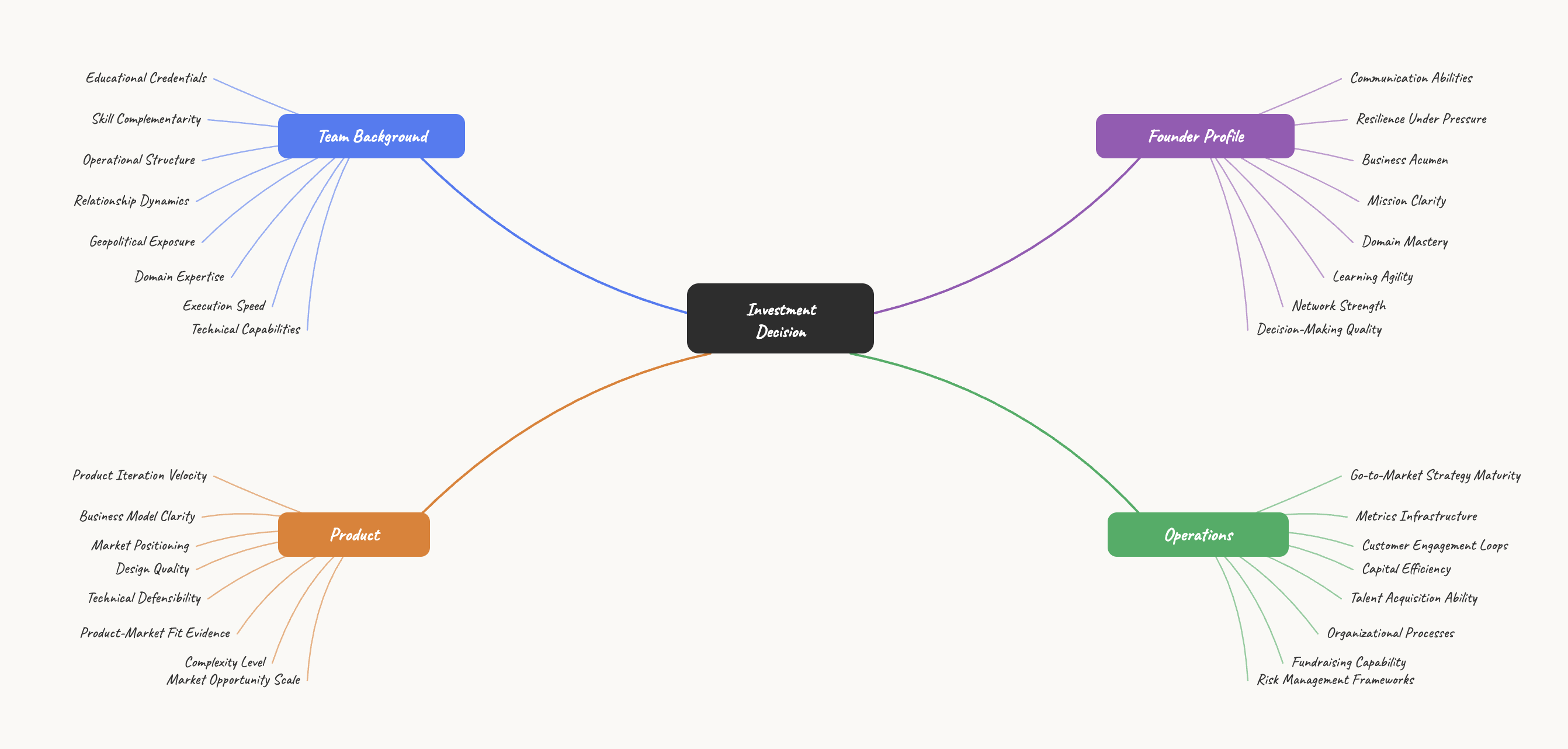
Mind map: brainstorming the 32 factors that shape an investment decision across four dimensions.
The problem
Strong intuition, weak calibration.
The issue isn't that investors can't make judgments — anyone engaging in AI-native primary market investments needs a tool to validate their intuition:
Each evaluation starts from scratch, resulting in high cognitive load and difficulty maintaining consistent standards.
It's challenging to place a specific team within a larger sample space for assessment, leading to strong intuition but weak calibration.
Solution
Step 1. A 32-question assessment framework.
I extracted investment insights from VC literature and blogs, then condensed them into four major dimensions. Each dimension contains eight questions, totaling 32 quantitative questions scored on a 1–5 point scale — minimizing vague adjectives. Each question maps to a specific piece of publicly available information (founder's thesis, GitHub commits, early customer case studies), reducing purely subjective scoring.
Sample questions from the Team Background section of the assessment framework.
Step 2. Excellence comes from comparison.
I selected 24 AI-native companies that demonstrated outstanding early performance — spanning model layers, application layers, and infrastructure. Using only publicly available information from their early stages, I applied the same 32-question assessment to each founding team and product. This yielded a distribution of "success samples": identifying which dimensions consistently scored high, where significant variations occurred, and which combinations showed strong correlations.
A raw score in isolation is meaningless. A team scoring 4.2 tells you nothing — but a team scoring 4.2 when the benchmark median is 4.6 tells you everything. The value of the benchmark table lies not in the numbers themselves, but in the context they create for comparison.
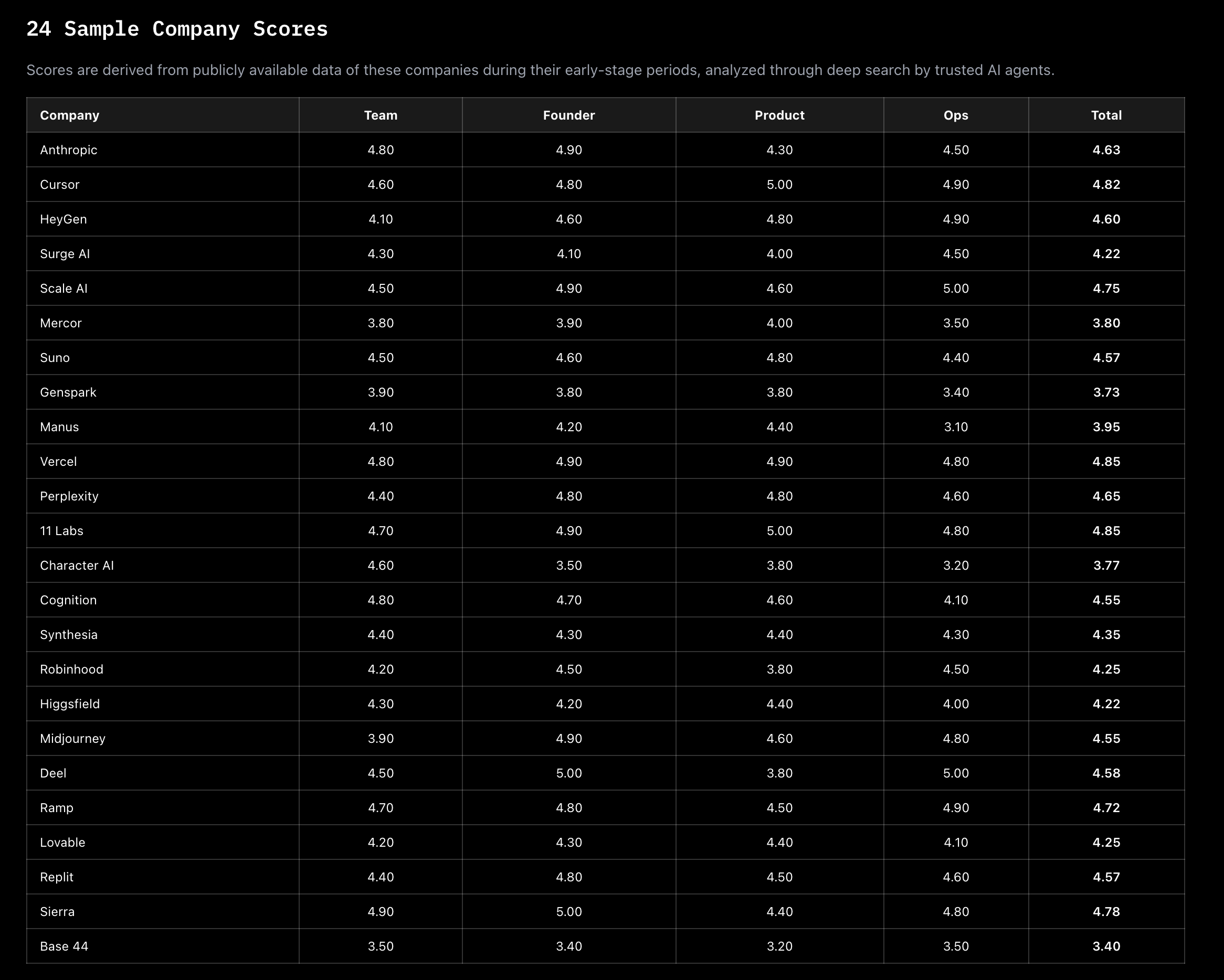
Scores derived from publicly available early-stage data, analyzed through deep search by trusted AI agents.
Signal-32 live demo: entering a startup and receiving a scored breakdown with benchmark comparison.
The outcome
Validating intuitions, not replacing them.
In a small-scale pilot, several decision-makers noted that the tool's greatest value lies not in "scoring," but in validating certain intuitions.
"The teams often have different perspectives after an hour-long chat with founders, yet share common insights in certain areas — this tool effectively distills those key questions."
For me personally, this project provided practice in combining VC qualitative experience, public data, and simple statistical tools into a reusable decision-support product. It also helped me avoid a bad investment — in a short-term perspective, the assessment was correct, with that team scoring only 3.1. But this tool can't be used for evaluating long-term deals, because everything is dynamic.